Overview
The first stage of the data lifecycle is the planning stage. A clear and thorough data management plan is recommended for any citizen science project that will collect and produce data. The plan needs to outline the expectations for collecting, using, and managing the data prior to data collection. Having a clear data management plan and consistently referring to it throughout a project promotes the integrity and consistency of the data produced and prevents future issues with data collection and publication. Data archive centres (DACs) can provide assistance with identifying standards, choosing a publication license, establishing a data flow pathway, and providing general data management support.
Activities
Data collection protocols
Following nationally and internationally recognised protocols and standards ensures that data collected by citizen scientists can be verified, replicated, and understood, maximising its usability in the future. Determining the protocols that will be used during data collection events during the planning stage, allows sufficient time and resources to be allocated for developing and testing of tools and resources as well as training staff and participants, reducing the risk of errors. Selecting sampling protocols at an early stage can also help to ensure that data collection forms can be designed to capture enough metadata to comply with standards, to be able to conduct a thorough quality assurance procedure at a later stage, and to support the Reusability aspect of the FAIR data standards.
Specific protocols exist for many types of collection events. In the UK, UKDMOS contains many of the UK government agencies’ protocols and standards for marine monitoring programmes carried out in the UK and Europe. Specific projects and sampling techniques can be searched for in the directory, and the resulting metadata will provide references to standard protocols used, as well as when and where individual samples are collected. For example, JNCC's Guide to Fisheries Data Collection and Biological Sampling (Doyle, A., Edwards, D., Gregory, A., Brewin, P. & Brickle, P. (2017). T2T Montserrat; a guide to fisheries data collection and biological sampling. JNCC.) is referenced in UKDMOS. However, a wide variety of data collection protocols can be found in the directory. In instances where a protocol does not yet exists, existing standards may be used to guide the development of new protocols. If these are developed as part of governmental monitoring programmes, they can be added to UKDMOS here, or by contacting the relevant organisation hosting the standard protocols e.g. JNCC's Marine Monitoring Method Finder.
The sampling design may have an impact on the design of data collection tools and resources needed. For example, if a survey is conducted across a vast area e.g. different areas in the UK, using an automated data submission system would ease data submission at a later stage, rather than needing to compile paper records in one physical location. When a citizen science project intends to collect data at specific sites, it is beneficial to determine where the survey events will occur (spatial coverage) as well as when and where individual samples will be collected (spatial resolution). Research has shown that data from citizen science projects with greater spatial coverage, and an increased spatial resolution are used more widely in research as the data have a smaller size of minimum and major spatial units, facilitating their use in species distribution modelling and conservation planning. These data with large spatial coverage may be from a series of organised events at specific locations around the country, or projects where users choose where they wish to record data e.g. anywhere in the UK.
Recommendations
- Select a standard data collection protocol if it exists, or if new protocols are developed, aim to follow exisiting standards and outline this in the data management plan
- Determine the likely and required spatial coverage of the project
Data collection tools
Data collection tools can consist of mobile applications, websites, computer programs, and physical tools such as measuring devices, collection instruments, observation tools and identification guides. Things to consider with any chosen data collection tools are:
- How easy or difficult they are to use. The difficulty of using the tools will influence the training required to provide participants with an adequate proficiency to minimise errors during data collection. If the tools are very complex, it can also deter more casual participants from joining the citizen science project; however, offering in-depth training might alleviate these challenges whilst providing the opportunity for volunteers to upskill.
- Cost of obtaining and distributing the tools to volunteers. Depending on the funding available, compromises may need to be made, so how this may affect the data produced should be taken into consideration. For example, if a small number of identification guides, or GPS devices are to be shared among the participants, this is likely to affect the accuracy of the records so additional on-site verification of species identifications and coordinates may be required.
- If volunteers have to purchase their own tools. This may create a barrier to engagement for participants of lower socioeconomic status. Conversely, it may also increase repeated engagement from the same volunteers once they have the required tools.
- Risk of damage or loss at survey sites. A contingency plan should be devised in case of sampling equipment being lost or damaged to enable the data collection to continue, for example, having a few spares of tools that are most likely to be damaged, or limiting the use of these to staff and more experienced volunteers.
- Limitations of the tools. A common limitation when conducting marine and coastal surveys is reduced phone and internet signal. If this is an issue in the intended survey locations, a mobile application that operates off-line would be a priority. Similarly, tools need to be suitable to the environment of the survey, and people might not be willing to use their own personal electronic devices in the marine environment. For example, if collecting image data of species in a snorkel or dive survey, cameras must be waterproof to the appropriate depth and produce images of a high enough resolution to enable identification of taxa from the images.
- Accuracy and precision of the tools. This will include determining how precise the measurements need to be e.g. recording distances to the nearest cm or to the nearest m, and how accurate they are e.g. by calibrating measurement devices to ensure the measurements collected reflect the true value.
Recommendations
- Plan which tools are required, accounting for any training required for staff and/or volunteers to use them.
- Reflect on cost, accuracy, precision, and suitability to the environment.
Case Study
iNaturalist is a web-based platform which can be accessed via the website, or via a mobile application. It has been used for many past citizen science events such as The Rock Pool Project’s Changing Tides Bioblitz, the Time and Tide Bell project, and Crab Watch EU. When using the app to upload a sighting, a photo is taken through the app, and provided there is sufficient signal, an exact coordinate and time of sighting is recorded. It also is able to provide suggestions for the identification of the taxon based on the photograph taken, allowing users to compare their record to other images to identify the taxon. It is free, easy to use, and only requires users to have a smartphone, making it a popular tool choice for many citizen science projects.

Licensing and permissions for data collection
When organising a data collection event in which volunteers will participate, there may be restrictions associated with the sampling area. For example, if it is private land or a protected area, the relevant authorities or landowners should be contacted to reach an access agreement, and to receive prior approval for surveys and scientific monitoring. They may also provide specific rules which must be followed when accessing those areas which would need to be communicated to all participants prior to arriving on-site. Failure to obtain the required access permissions could result in an inability to use any collected data, or could prevent the data collection event from taking place. In addition to this, certain species require a license to be surveyed, further information on which species is available here.
Participants should grant permission for the data and media they collect to be used for research purposes, publications, reports etc and if the project wishes to take photographs to be shared, on social media for example, permission must be granted prior to the collection event. Participants may also take their own photographs or collect additional data which could be supplied to the project as supplementary data. The conditions of use should be agreed with the participants. In a permissions form, it may be useful to separate conditions for data/media access and reuse from permissions to use in social media and advertising as some participants may grant permission for data to be used in reports, but not on social media, for example.
In addition to this, when conducting a thorough quality assurance, the data collector may need to be contacted to confirm details of the records, so some basic contact details for participants may need to be retained until the data has been through its QA. However, personal data should be limited to only collect what is relevant and necessary. If any personal data i.e. information that relates to an identified individual, is collected a plan must be in place to comply with GDPR guidance and regulations for data sharing under the Data Protection Act 2018. This will include ensuring personal data is processed securely, potentially by using pseudonymisation and encryption to enable data confidentiality, integrity, and availability.
Recommendations
- Plan and seek any permissions that may be required for the task, including access permissions from landowners, consent from participants to use the collected data and media such as photographs for analyses, research and publication and whether these can be used for social media and advertising purposes.
- Plan the creation of permission forms for the use and storage of personal data to comply with GDPR regulations, keeping this to only data that is necessary.
Case Studies
Lundy Marine Protected Area
Lundy Marine Protected Area provides guidance on the website on permitted activities, and those that require anyone wishing to conduct surveys and scientific monitoring to consult with the warden. The warden could also be contacted to determine whether there are specific requirements to share data with the Lundy Marine Protected Area upon completion of the project, and whether they require acknowledgment in publications created from these data.
Marine Biological Association Bioblitzes
The Marine Biological Association has run Bioblitzes since 2009. A Bioblitz is a short-term data collection event in which participants aim to record as much as they can within a set area to provide a snapshot of biodiversity in that area. Participants were asked to complete and sign a permissions form granting the use of any photography taken at the event in future publicity and social media posts linked to the event. Additional permissions can be requested to this sort of form such as permission to use images taken by volunteers for future species verification. An example image permissions form from the MBA.
Use of Images
By contributing photographs (and/or video) to the Data Desk at the MBA Bioblitz, you have agreed that your images/ videos can be used to support records submitted during the Bioblitz event during [insert date]. Please delete as appropriate which use(s) of your photos which you give permission. Contributors retain the copyright of their images.
Photographs and/or videos may be used (please delete as appropriate):
- For promotional use for future MBA public events: YES / NO
- In documents relating to the event (e.g. report and website): YES / NO
- On the MBA Social media pages: YES / NO
- In posters and/or presentations associated with the MBA Bioblitz: YES / NO
If images are required for commercial purposes or for wide dissemination, the image provider WILL be contacted for permission directly and in the form of an acknowledgement obtained from the owner.
Image provider details
In order to ensure that we can contact image providers, please provide the following contact details.
Full name: ………………………………………………………………………………………………………………………………………………………
Contact address: ………………………………………………………………………………………………………………………………………
Email address: ……………………………………………………………………………………………………………………………………………
Image provider permission
I agree to the use of my images as specified in the above terms and conditions
Full name: ………………………………………………………… Signature:……………………………………………………
Date: ……………………………
Verification and quality control (QC) schemes
Data verification methods to be conducted at the collection event and any relevant quality control (QC) schemes should be determined within the data management plan. Verification can involve the checking of records at the site by subject experts to ensure records are accurate and to reduce the risk of species misidentification, or the incorrect recording of coordinates. A trial collection event conducted by professionals carried out prior to the citizen science event can help to mitigate errors and improve accuracy by identifying potential risks, developing further training where necessary, and providing a baseline data collection standard to which the citizen science data can be compared.
Data verification following a data collection event ensures that data and taxa identifications are accurately recorded. Verification processes can be built-in to the platform where data will be recorded, for example iNaturalist and iRecord, or it may need to be planned separately if the citizen science project intends to publish records via a different route, e.g. as a whole survey to a data archive centre. This could involve collecting samples at the site of data collection and having an expert in that taxonomic group identify the taxa at a later date. Another example of data verification is the process the Zooniverse uses in projects where images are analysed by multiple volunteers. This differs from data validation, which may involve automated processes to validate that data are in the correct format and meet the required data standards.
The NMBAQC scheme describes the importance of collecting a voucher/reference collection when recording biodiversity data to be used as a reference for future identification of taxa or habitats. This voucher specimen can be a preserved specimen, or clear images of the specimen or habitat.
Another quality control method is to repeatedly sample the same area and obtain an average of results, which may be more suitable for projects where the sampling area is relatively small and there are sufficient participants to repeat sampling. Quality control differs from quality assurance (QA), as QC involved checking the data for errors e.g. bias and systematic errors, and recorded correctly prior to submission to a DAC, whereas QA assesses the data are correct, accurate, in the correct format and that it meets data standards, and may include a validation step prior to publication, and this step may be carried out by the DAC which will archive and publish the data.
By outlining the verification and QC methods which are expected to be carried out at the data collection in the data management plan, the methods can be standardised across survey sites and any additional training, equipment or staff required can be planned well in advance.
Recommendations
- Outline any on-site and post-collection data verification methods and data quality control (QC) schemes in the data management plan
Training
Participants will need the appropriate skills to conduct the tasks required during the citizen science project. Outlining the training requirements in the data management plan enables sufficient time and resources to be allocated for training participants, both volunteers and staff, before starting to collect data. Training sessions may focus on the preparation for the event, what to do during the event or how process the data following the event. Training must be tailored to the complexity of the data collection protocols, equipment used and the experience level of the participants. Training may occur before, at the start of a data collection event, or after if focused on data management. The following elements should be considered when planning training resources:
- Complexity of collection methods. Complex sampling methods will require more extensive training thus benefiting from closer supervision by either professional scientists or volunteers with previous experience with similar techniques. Complex methods are also more likely to incur errors, so reducing the complexity as much as possible reduces the risk of bias and systematic errors. This can be achieved by breaking down complex tasks into easier tasks, e.g. when recording species in biodiversity surveys, splitting the volunteers into groups and allocating a subset of species for them to record allows them to become more familiar and skilled at identifying those taxa.
- Equipment used by volunteers. Similar to the complexity of collection methods, equipment that is more difficult to use will require further training and supervision by those who are more skilled in the use of the collection tools.
- Experience level of citizen scientists. Volunteers that have completed more advanced training, are likely to produce more high-quality data. Less experienced participants will require more comprehensive training. A buddy or group surveyor system can be beneficial for surveying events where there is likely to be a range of abilities, pairing experienced participants with less experienced volunteers.
- Standardisation of training resources and programmes. If the project is to be carried out in different locations, the training provided to participants should be consistent across locations to ensure the data collected is of the same quality. This can be achieved by having an overarching training curriculum followed by all those providing training to volunteers, using the same training resources wherever possible. Online training sessions are an effective way of delivering training to people in different locations, or funding an in-person workshop in a centralised location. Prior testing participant abilities can improve reliability but can be a barrier to participation if requiring significant learning time.
Training materials can consist of pre-collection training such as courses (online or in-person), assignments to get participants familiar with the collection methods and the data handling required, video tutorials, identification guides and survey technique guides. Data-focused training resources can be found in the Citizen Science Training Portal.
Recommendations
- Outline training in the data management plan, considering complexity of data collection protocols, equipment used, experience level of participants and the requirement for standardisation of training materials.
Case Study
Seasearch is a citizen science project that aims to record marine habitats and species around the UK coasts. The training programme is split into four levels of progressing difficulty, encouraging volunteers to progress through the training as they become more experienced surveyors and giving an incentive to continually participate in surveys to improve their skills. Courses consist of either online or in-person sessions, and completing practice survey forms. Identification guides and training materials are included in the cost of each course, so volunteers can review the resources at any time. Trainees must then put the skills to practice by carrying out qualifying surveys supervised by a tutor. Once qualified, the volunteers are able to join as many or as few surveying events as they like, and have the opportunity to continue more specialised training if they wish to do so. As Seasearch relies on trained divers and snorkellers, survey training and support is a crucial part of the project.
Data standardisation
Data standards are a set of rules for formatting data to make them consistent across datasets. Complying with data standards enables the data to be interoperable and reusable, so they can be shared with national and international data aggregators, used for a wide variety of work. Being interoperable and reusable means the data has a greater impact as they can be used in environmental monitoring programmes, they can inform essential biological variables (EBVs) and essential ocean variables (EOVs), and can contribute to initiatives like the UN Ocean Decade, as well as the Marine Strategy Framework Directive.
Data standards should be determined prior to data collection as this will help to identify which data fields are mandatory to complete in order to comply with the standards e.g. survey date, survey location, sampling devices. Doing this early on means that you will be able to ensure this important information is captured as standard from the beginning of the project.
The standards selected will depend on the type of data collected and the theme it falls under. In the UK, MEDIN is the network of marine-focused data archive centres that contribute to the creation of marine data standards and implement the adherence to these. MEDIN standards are categorised by marine data theme e.g. biodiversity, oceanography, meterology, with templates and data guidelines that data providers can complete to ensure their data are compliant by completing all mandatory fields. Data that are MEDIN.compliant are also GEMINI (national) and INSPIRE (global) compliant, which means they comply with national and international standards. These data can also then be transformed into other data standards such as DarwinCore when published to enable interoperability and the harvesting of data by aggregators such as OBIS. Other common data standards are Ecological Metadata Language and BioCASe / ABCD.
Recommendations
- Identify appropriate data standards for the data being collected and determine which mandatory information needs to be recorded during the data collection event. If data are to be submitted to a MEDIN DAC, choose the appropriate MEDIN data guideline.
Metadata
Metadata is data that provides information about other data. It provides information to data users which help them to understand the data and how they can be used without needing to contact the data provider. When a dataset is published, a metadata record should also be published alongside it. A metadata record provides detailed information such as:
- who owns the data
- any access and reuse restrictions
- any unique identifiers for the dataset
- the date it was collected and published
- where it was collected
- where to access it
- who to contact if there are any questions about the dataset
Metadata records should also comply with standards. To produce a high-quality metadata record the standards should be researched prior to collection events to ensure all mandatory information is recorded. MEDIN metadata records comply with the MEDIN Discovery Metadata Standard, and are published on the MEDIN Discovery Metadata Portal, where users can search for datasets and their metadata. Metadata records published on the MEDIN Portal are then shared and made findable on the Ocean Info Hub.
Recommendations
- Research metadata standards in the planning stage to ensure all mandatory information is collected in the data collection and processing stages.
Data processing tools
Once the data have been collected, they may need to be processed to put them into a format which can facilitate data standardisation, quality assurance and publication. This can involve digitising paper records, scanning documents, or identifying taxa from photographs and videos. The processing steps should be outlined in the data management plan along with any tools required. This will enable sufficient training and resources to be allocated for effective processing of the data. For example, if data will be processed using an automated script, personnel must have the appropriate skills and software to do this. Examples of data processing tools may include Microsoft Excel, Python, R package., QGIS, or coordinate conversion scripts.
Recommendations
- Define data processing tools in the data management plan to allocate appropriate training and resources.
Quality Assurance (QA)
Quality assurance (QA) of data and metadata is carried out after any data processing, and aims to identify and correct any mistakes that may exist in the data produced by a project. The main areas that should be assessed during the QA of a dataset are spatial accuracy, taxonomic accuracy, methodological consistency, and temporal accuracy. Adherence to the selected data standards is also checked during the quality assurance of data and metadata, prior to validation of the dataset against specific standards to minimise corrections required at a later stage. When submitting data to a data archive centre (DAC), as much information as possible should be provided to the DAC so they can carry out a thorough QA of the data. This information can include any raw data, including original paper records if relevant, any images collected, GIS files, videos, contact details of the data provider, any relevant documentation such as project reports, vessel reports or logs. By establishing the QA procedures at an early stage in a citizen science project, a checklist can be made of information that must be retained for effective QA of the data.
When quality assuring the data and metadata, a variety of tools could be used, such as Microsoft Excel formulae, R package., taxon match tools, e.g. WoRMS and MSBIAS, coordinate converters, geographic mapping software like QGIS or Google Earth. If submitting data to a data archive centre like DASSH, you may not need to conduct the quality assurance yourself as they may have their own quality assurance procedures. The relevant DAC should be contacted to discuss data requirements for conducting their QA procedures. A list of MEDIN data archive centres and their contact details can be found on the MEDIN website.
Recommendations
- Outline the quality assurance procedures in the data management plan to determine which data need to be retained for effective data QA.
- Contact DAC to establish whether they have their own quality assurance procedure and if so, what information they require to conduct a QA of the submitted data.
Data Archive Centres (DACs)
Data archive centres (DACs) archive and publish data, making them available for a wide range of users and data aggregators to harvest and use. They can also provide data-focused leadership, best practices, services, tools, and training to support the archiving and publication of data in a standardised format. This ensures data is findable, accessible, interoperable and reusable, or FAIR.
MEDIN, the Marine Environmental Data and Information Network, consists of 10 data archive centres which specialise in archiving different types of data including fisheries, water column oceanography, meteorology, bathymetry, historic environment, geology and geophysics, flora, fauna and habitats.
The relevant DAC should be contacted during the planning stage to be well informed of the data submission process, standards used, and any further requirements. If you are unsure about which DAC the data from your citizen science data should be submitted to, or have any questions, you can contact the MEDIN team at enquiries@medin.org.uk.
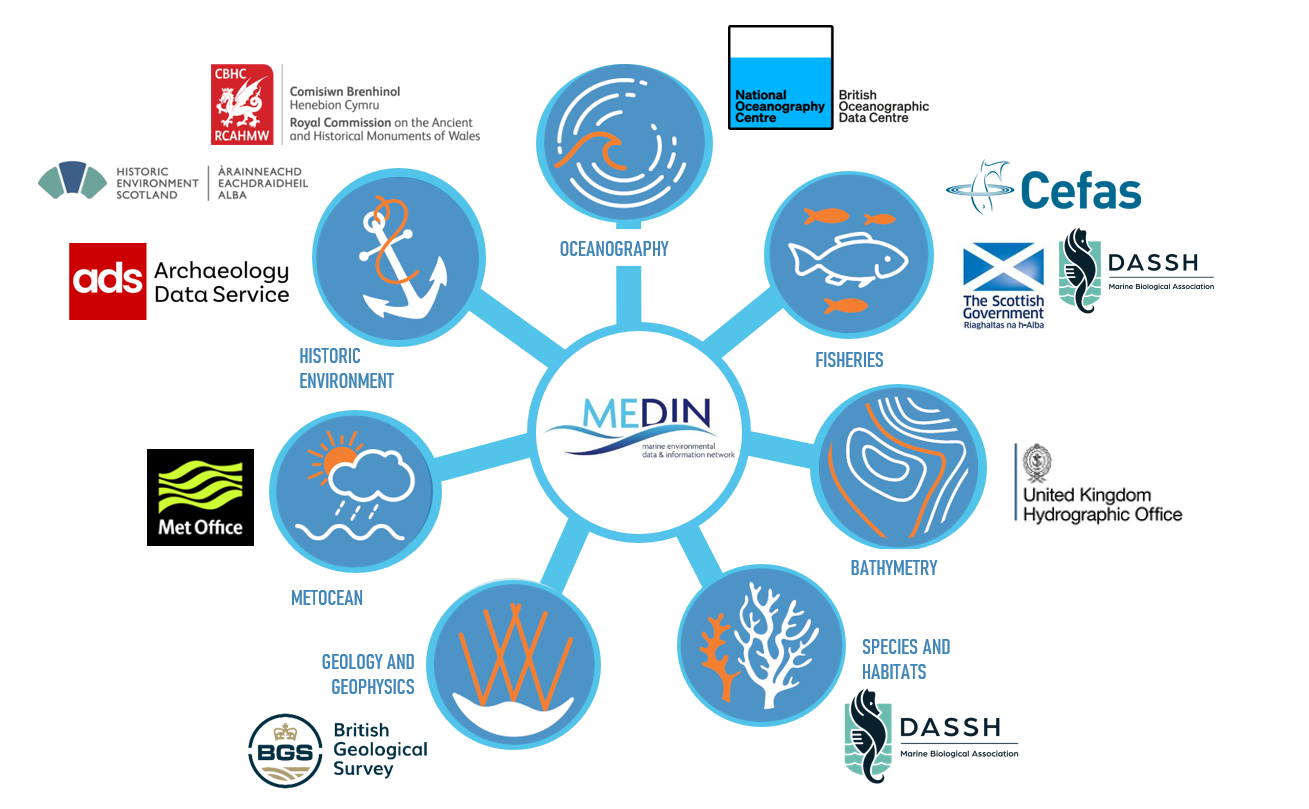 Figure 1: Data Archive Centres
Figure 1: Data Archive Centres
If the citizen science project has received funding, the archival and publication of (meta)data with a DAC might be a requirement. Even if this is not the case, it is still strongly recommended to do this to ensure data are FAIR and their longevity is maximised well beyond the lifespan of the citizen science project.
Recommendations
- Specify the data archive centre you will archive and publish data through in the data management plan.
- Contact the data archive centre at an early stage to receive specific guidance relevant to your data.
Case Study
The Marine Biological Association and the Natural History Museum established the Mitten Crab Watch project to encourage citizen scientists to record sightings of the invasive non-native species, the Chinese mitten crab (Erocheir sinensis). In the past, the MBA hosted a website for submitting sightings which shared records to the Biological Records Centre, which shares data with NBN Atlas. The MBA no longer organises citizen science activities directly relating to this project, but provides support and guidance for those wishing to find out more about Chinese mitten crabs and submit their sightings.
Data flow pathway
The knowledge that their data will be contributing to science, public information and conservation can motivate citizen scientists to take part in a project. Determining the pathway the data will take once collected, and communicating this to potential volunteers when advertising the event could also increase the number of participants and the quantity of data that can be collected.
The type of data recorded by citizen science projects, as well as the intended degree of sharing of the data will influence the pathway those data will take. For example, single records submitted by users of iNaturalist will follow the route in Figure 2. These data are more likely to be collected by casual citizen scientists recording ad-hoc sightings, but individual record submission platforms like iNaturalist and iRecord can also be used to aid data submission from organised data collection events. Larger datasets are more likely to be archived and published by data archive centres like DASSH (marine biodiversity and habitats data); the pathway these data take from DASSH are also shown in Figure 2.
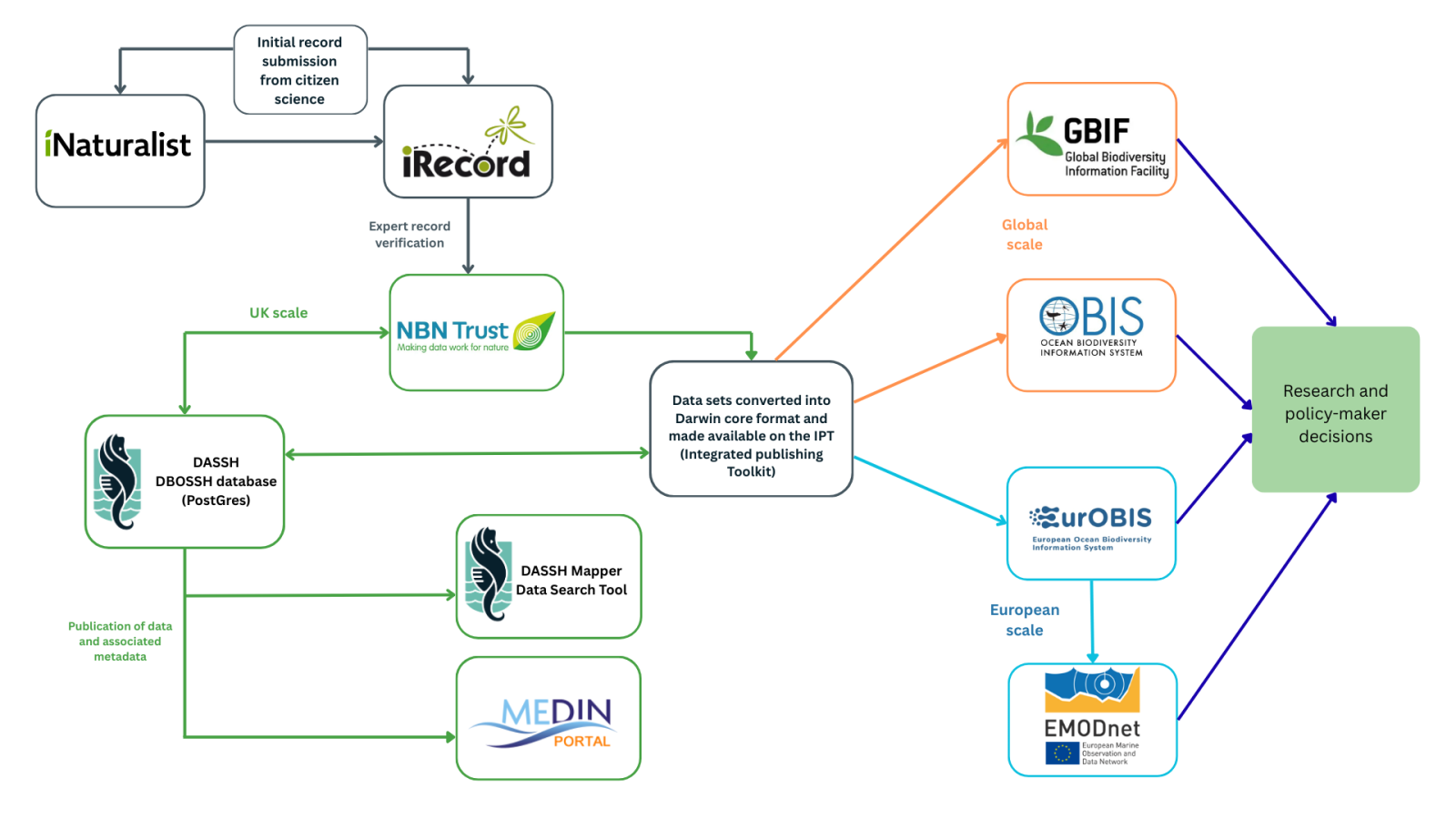
Figure 2: DASSH data flow
Recommendations
- Determine the route the data will take once collected, considering whether they will be submitted as individual records or whole datasets.
- Plan to communicate the data pathway clearly with citizen scientists to increase future engagement.
Case Study
The Rock Pool Project has been clear with volunteers regarding the pathway their data travels through, communicating this via training presentations prior to their citizen science events. Figure 3 shows the flow diagram they have shared with participants.
 Figure 3: Data flow from The Rock Pool Project.
Figure 3: Data flow from The Rock Pool Project.
Licensing and permissions for data re-use
All high-quality data produced by a citizen science project should aim to be FAIR: findable, accessible, interoperable and reusable. This can be achieved by complying with data and metadata standards, making these openly available to users in an interoperable format, and as openly accessible as possible. By researching data licenses and reuse conditions at this stage, the collaboration with data archive centres can be started at an early stage, and it allows enough time to liaise with funders and data owners about how the data will be shared upon completion of the project or data collection event.
If volunteers are collecting and submitting data directly (e.g. through a mobile app) then you may want to consider providing guidance/training on data licensing and how to select the appropriate license to ensure maximum usability. For example, the default license for iNaturalist submissions is CC-BY-NC which restricts the use of data for commercial purposes, so users are encouraged to change this a more open license such as CC-BY.
Recommendations
- Outline any conditions to data sharing, access and reuse the data produced by the citizen science project will have in the data management plan.
Maintainance
After a dataset is published or archived, data maintainers will be responsible for making amendments to the dataset itself or to the associated metadata. This may occur if the ownership of data changes, if the title changes to match a publication, if amendments are made to records, or if the further surveys are carried out in the future which are part of the same project and so can be linked together via a series. If the data are published via a data archive centre, an agreement can be made for the DAC to be responsible for the updates, or the data owners or other named organisation can carry out any updates. To ensure data remain accurate and reusable, it is important that the maintainers are specified when data are archived and published.
Recommendations
- Plan how data resulting from the project will be maintained and by who, should the project end, corrections be required, or additional data be added at a later stage.
Case Study
The MBA Bioblitzes have been carried out regularly since they began in 2009. The individual Bioblitz events form part of an overarching series (see metadata record here), so as new bioblitzes are carried out, their metadata can be linked together in this parent series metadata record. As DASSH is the DAC that archives and publishes the MBA's bioblitz data, DASSH is responsible for making any changes to the series metadata record, the DOI, and the datasets as and when required.
Summary & Checklist
A citizen science project that produces high quality, FAIR data, should cover the following points in the data management plan:
- Select a standard data collection protocol, if it exists, or if new protocols are developed, aim to follow exisiting standards, and outline this in the data management plan
- Determine the likely and required spatial coverage of the project
- Plan which tools are required, accounting for any training required for staff and/or volunteers to use them
- Reflect on cost, accuracy, precision, and suitability to the environment
- Plan and seek any permissions that may be required for the task, including access permissions from landowners, consent from participants to use the collected data and media such as photographs for analyses, research and publication and whether these can be used for social media and advertising purposes
- Plan the creation of permission forms for the use and storage of personal data to comply with GDPR regulations, keeping this to only data that is necessary
- Outline any on-site and post-collection data verification methods and data quality control (QC) schemes in the data management plan
- Outline training protocols, considering complexity of data collection protocols, equipment used, experience level of participants and the requirement for standardisation of training materials
- Identify appropriate data standards for the data being collected and determine which mandatory information needs to be recorded during the data collection event. If data are to be submitted to a MEDIN DAC, choose the appropriate MEDIN data guideline
- Research metadata standards in the planning stage to ensure all mandatory information is collected in the data collection and processing stages
- Define data processing tools in order to allocate appropriate training and resources
- Outline the quality assurance procedures to determine which data need to be retained for effective data QA
- Contact DAC to establish whether they have their own quality assurance procedure and if so, what information they require to conduct a QA of the submitted data
- Specify the DAC you will archive and publish data with
- Contact the DAC at an early stage to receive specific guidance relevant to your data
- Determine the route the data will take once collected, considering whether they will be submitted as individual records or whole datasets
- Plan to communicate the data pathway clearly with citizen scientists to increase future engagement
- Outline any conditions to data sharing, access and reuse the data produced by the citizen science project will have
- Plan how data resulting from the project will be maintained and by who, should the project end, corrections be required, or additional data be added at a later stage